
安全可视化普及系列一:你的网站安全吗?
黑客的每一次网络攻击都是从信息收集开始,也就是我们常说的扫描,按网络协议分层思想,扫描也可以分为以下三类(暂不考虑社会工程学范畴的扫描):
1 网络层扫描
主要是基于IP协议的扫描和探测,用以获取目标的网络拓扑,设备防火墙和链路通讯状况,该阶段的扫描,并没有建立连接,常用的工具有:traceroute 和 Ping.
Traceroute的工作原理:首先,traceroute会发出一个TTL是1的IP datagram(其实,每次送出的为3个40字节的包(包的字节大小可以修改,但需要尽量小,便于传输),包括源地址,目的地址和包发送的时间标签)到目的地,当路径上的第一个路由器收到这个datagram时,它将TTL减1.此时,TTL变为0了,所以该路由器会将此datagram丢掉,并回送一个[ICMP time exceeded]消息,tracertoute收到这个消息后,就知道这个路由器存在这个路径上,接着tracertoute再送出另一个TTL是2的datagram,发现第二个路由器……, traceroute 每次将送出的datagram的TTL 加1来发现另一个路由器,这个重复的动作一直持续到某个datagram 抵达目的地。当datagram到达目的地后,主机会送回一个[ICMP port unreachable]的消息,而当traceroute收到这个消息时,便知道目的已经到达了。
2 系统层扫描
主要是基于TCP/UDP协议的扫描和判断识别,该阶段的扫描,有连接的建立,常见的方式有端口扫描,服务识别,漏洞扫描等,主要的工具有:nmap
3 应用层扫描
这里主要是基于应用层协议的扫描和漏洞的识别,该阶段的扫描,属于TCP全连接。而对于个人网站服务器常见的应用服务有:FTP,HTTP,SSH等,这些都会成为攻击者的入口点。
下面我们来对一个没有加入安全宝的网站进行一次简单的扫描,看看攻击者都能获取那些信息,对你的网站会造成威胁吗,这里就拿站长之家网站来单纯地进行扫描说明,并不会进行恶意的后续攻击,
1 利用traceroute进行网络层的扫描探测
Traceroute –q 4 www.chinaz.com
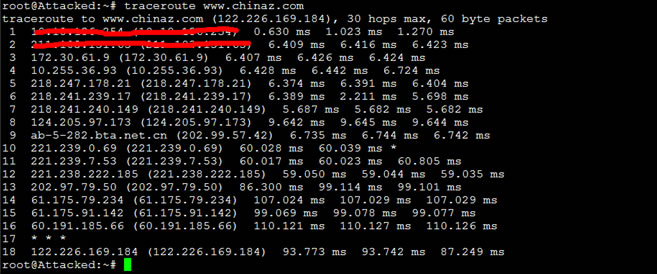
从上面的节点信息我们看出,在站长之家网站的前一个节点并没有获取到,但实际上我们是可以接收到网站服务器的ICMP返回信息,因此有可能是DNS解析过慢或前端有防火墙设备屏蔽掉ICMP返回信息,那么我们接着用如下命令排除下问题:
Traceroute -n -q 4 www.chinaz.com

从上面的内容看出,仍然没有第17个节点的信息,因此我们可以推断第17个节点应该会是防火墙设备,屏蔽了ICMP的返回信息。
2 利用Nmap进行系统层的扫描
在扫描的过程中,发现站长之家前端有三台CDN服务器作为负载均衡,这里也并不是恶意的扫描,因此还是用对域名的扫描来作演示,具体攻击会指定IP来进行探测。
扫描开放端口
Nmap –p 1-65535 www.chinaz.com
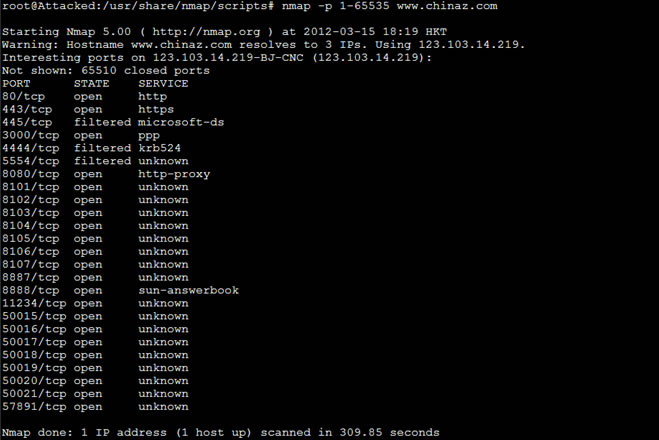
扫描主机系统
Nmap -O www.chinaz.com
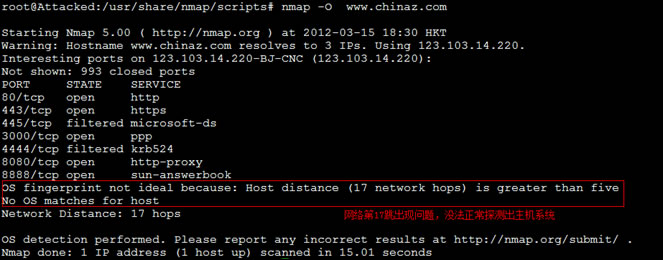
扫描服务版本
Nmap -sV www.chinaz.com
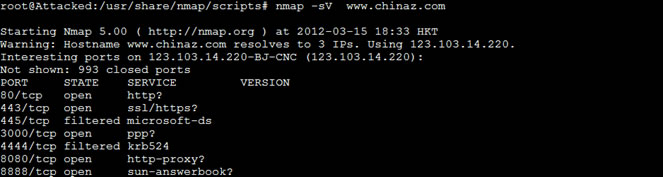
利用NMAP脚本引擎深度扫描
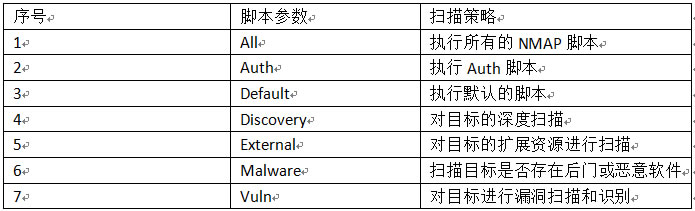
扫描远程主机和域上的帐号信息:
Nmap --script auth www.chinaz.com
(注:这里并没有探测到帐号信息,如果扫描器成功探测,或在端口信息的下方有帐号的信息。)
对目标进行深度扫描:
Nmap --script discovery www.chinaz.com

扫描目标是否存在后门和恶意程序:
Nmap --script malware www.chinaz.com
(注:这里并没有探测到帐号信息,如果扫描器成功探测,或在端口信息的下方有帐号的信息。)
扫描目标主机存在的漏洞:
Nmap --script vuln www.chinaz.com
(注:这里并没有探测到帐号信息,如果扫描器成功探测,或在端口信息的下方有帐号的信息。)
通过上面的扫描,我们已经获取到服务器开放的端口和服务,攻击者会根据服务器运行的服务来选择后续的攻击
3 利用网页扫描器进行扫描
这里主要以web应用为例进行说明,攻击者首先会按照以下的方式进行信息收集:
获取WebServer的banner信息
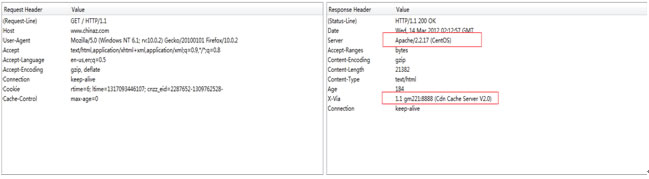
从服务端的返回信息,我们看到了网站后端实际上CentOS系统,运行着Apache服务;前端使用了三台Cdn 缓存服务器作负载均衡,它们的IP信息分别为: 123.103.14.219,123.103.14.220,123.103.14.221.
利用爬虫爬取网站的有效链接(参考开源项目:lynx)
利用字典进行Web目录的枚举(参考开源项目:DirBuster)
对网站链接和目录进行漏洞审计
由于后面三个步骤涉及到攻击范畴,这里就不作具体演示,从上面的过程中我们可以看出,其实攻击者首先会利用工具对目标进行扫描和信息收集,然后对这些获取的信息进行手工的分析和审计,我们在与攻击者对抗的过程中,实际上需要做的是在每个扫描环节对攻击者的行为进行干扰,阻碍其正常的判断。这里简单介绍下加入安全宝后,对攻击者这些扫描所产生的干扰:
1 网络层的扫描干扰
加入安全宝的网站用户,其对外的IP地址实际上是安全宝的Server IP,攻击者并不能有效地获取网站服务器的真实IP,因而也并不能对网站服务器的网络结构和拓扑进行真实地扫描。
2 系统层的扫描干扰
由于网站用户对外的IP实际上是安全宝的Server IP,而安全宝的Server 对外仅开放了80端口,因此攻击者也就不能有效的识别用户服务器其它的应用服务,规避了其它服务带来的风险。
3 Web扫描器的干扰
n 获取WebServer的banner信息 ----> 干扰策略: ASERVER/0.8.54-1
n 利用爬虫爬取网站的有效链接 ----> 干扰策略:对于一些扫描器的敏感标识进行拦截,无返回信息,阻碍爬虫对所有链接的爬取。
n 利用字典进行Web目录的枚举 -----> 干扰策略:对于一些扫描器的敏感标识进行拦截,无返回信息,阻碍扫描获取目录。
n 对网站链接和目录进行漏洞审计-----> 干扰策略:对于一些常见的漏洞,有漏洞规则的检测和拦截,阻碍漏洞利用程序正常的使用。
本页关键词: